Lecture 11: Reinforcement Learning
 HTML Slides
HTML Slides PDF Slides
PDF Slides(Deep) Reinforcement Learning
COMP 4630 | Winter 2026 Charlotte Curtis
Overview
- Terminology and fundamentals
- Q-learning
- Deep Q Networks
- References and suggested reading:
- Scikit-learn book: Chapter 18
- d2l.ai: Chapter 17
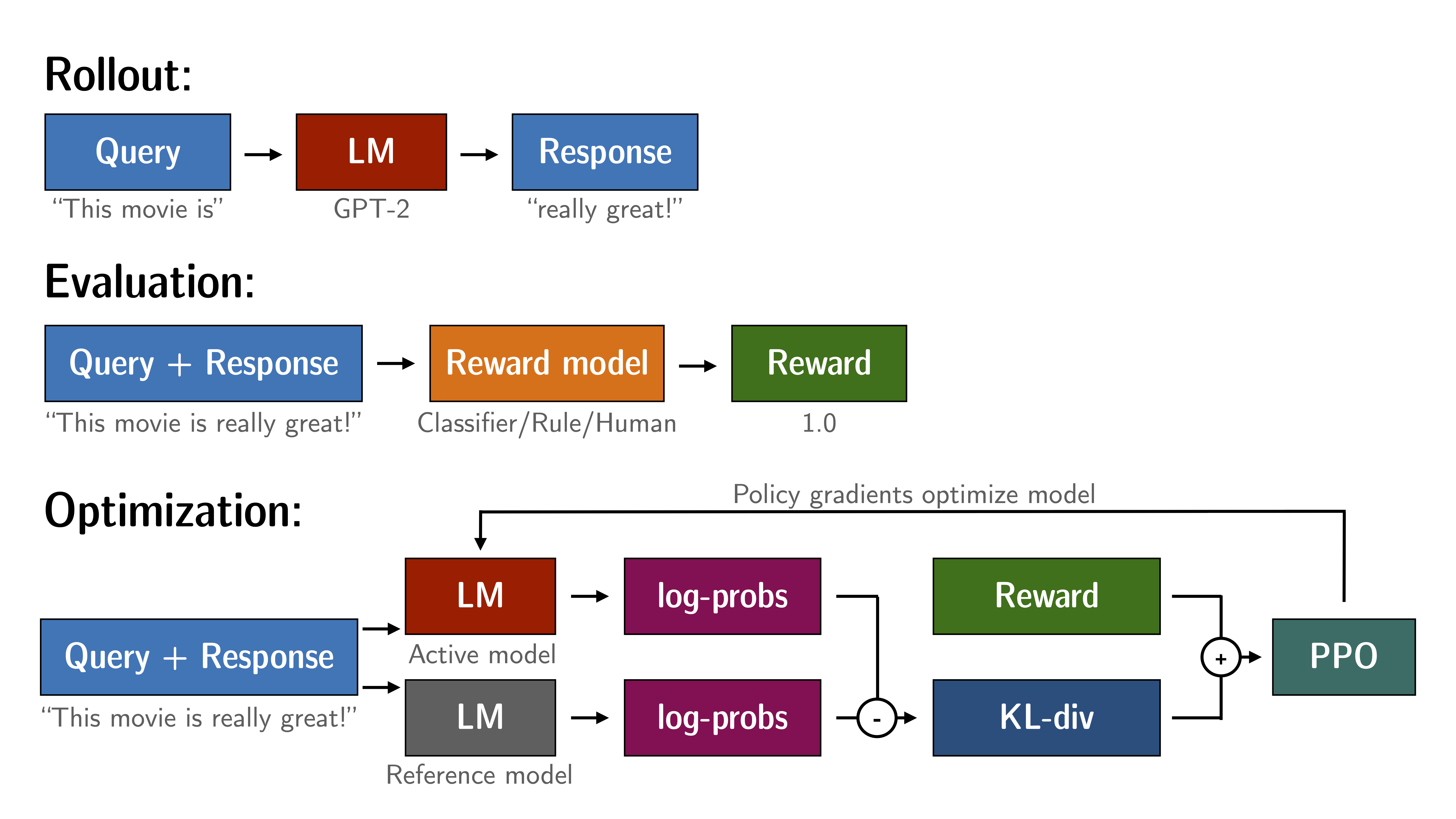
Reinforcement Learning + LLMs
Terminology
- Agent: the learner or decision maker
- Environment: the world the agent interacts with
- State: the current situation
- Reward: feedback from the environment
- Action: what the agent can do
- Policy: the strategy the agent uses to make decisions
Classic example: Cartpole
The Credit Assignment Problem
- Problem: If we’ve taken 100 actions and received a reward, which ones were “good” actions contributing to the reward?
- Solution: Evaluate an action based on the sum of all future rewards
- Apply a discount factor to future rewards, reducing their influence
- Common choice in the range of to
- Example of actions/rewards:
- Action: Right, Reward: 10
- Action: Right, Reward: 0
- Action: Right, Reward: -50
Policy Gradient Approach
- If we can calculate the gradient of the expected reward with respect to the policy parameters, we can use gradient descent to find the best policy
- Loss function example: REINFORCE (Williams, 1992)
where:
- = output probability for action given state
- = reward at timestep
- = model parameters
Value-based methods
- Policy gradient approach is direct, but only really works for simple policies
- Value-based methods instead explore the space and learn the value associated with a given action
- Based on Markov Decision Processes (review from AI?)
Markov Chains
- A Markov Chain is a model of random states where the future state depends only on the current state (a memoryless process)
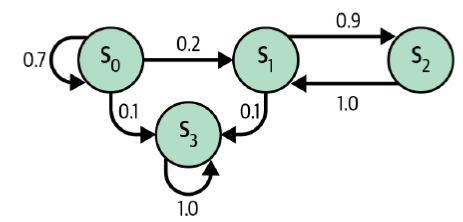
- Used to model real-world processes, e.g. Google’s PageRank algorithm
- ❓ Which of these is the terminal state?
Markov Decision Processes
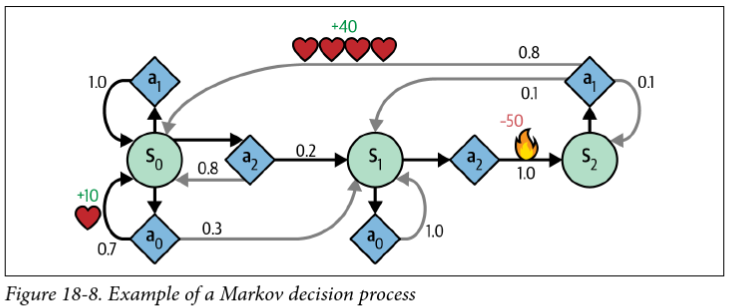
- Like a Markov Chain, but with actions and rewards
- Bellman optimality equation:
Iterative solution to Bellman’s equation
Value Iteration:
- Initialize for all states
- Update using the Bellman equation
- Repeat until convergence
Problem: we still don’t know the optimal policy
Q-Values
Bellman’s equation for Q-values (optimal state-action pairs):
Optimal policy :
For small spaces, we can use dynamic programming to iteratively solve for
Q-Learning
- Q-Learning is a variation on Q-value iteration that learns the transition probabilities and rewards from experience
- An agent interacts with the environment and keeps track of the estimated Q-values for each state-action pair
- It’s also a type of temporal difference learning (TD learning), which is kind of similar to stochastic gradient descent
- Interestingly, Q-learning is “off-policy” because it learns the optimal policy while following a different one (in this case, totally random exploration)
Q-Learning Update rule
-
At each iteration, the Q estimate is updated according to:
-
Where:
- is the estimated value of taking action in state
- is the learning rate (decreasing over time)
- is the immediate reward
- is the discount factor
- is the maximum Q-value for the next state
Exploration policies
- ❓ How do you balance short-term rewards, long-term rewards, and exploration?
- Our small example used a purely random policy
- -greedy chooses to explore randomly with probability , and greedily with probability
- Common to start with high and gradually reduce (e.g. 1 down to 0.05)
Challenges with Q-Learning
- ❓ We just converged on a 3-state problem in 10k iterations. How many states are in something like an Atari game?
- ❓ How do we handle continuous state spaces?
One approach: Approximate Q-learning:
- approximates the Q-value for any state-action pair
- The number of parameters can be kept manageable
- Turns out that neural networks are great for this!
Deep Q-Networks
- We know states, actions, and observed rewards
- We need to estimate the Q-values for each state-action pair
- Target Q-values:
- is the observed reward, is the next state
- is the network’s estimate of the future reward
- Loss function:
- Standard MSE, backpropagation, etc.
Challenges with DQNs
- Catastrophic forgetting: just when it seems to converge, the network forgets what it learned about old states and comes crashing down
- The learning environment keeps changing, which isn’t great for gradient descent
- The loss value isn’t a good indicator of performance, particularly since we’re estimating both the target and the Q-values
- Ultimately, reinforcement learning is inherently unstable!
The last topic: Geneterative AI and ethics


GenAI + Ethics Discussion
- Generative images have gotten really good
- What can we do? What should we do?