Lecture 10: Transformers
 HTML Slides
HTML Slides PDF Slides
PDF SlidesTransformers and Large Language Models
COMP 4630 | Winter 2026 Charlotte Curtis
Overview
- Attention mechanisms
- Transformers and large language models
- Multi-head attention, positional encoding, and magic
- BERT, GPT, Llama, etc.
- References and suggested readings:
- Scikit-learn book: Chapter 16
- d2l.ai: Chapter 11
Attention Overview
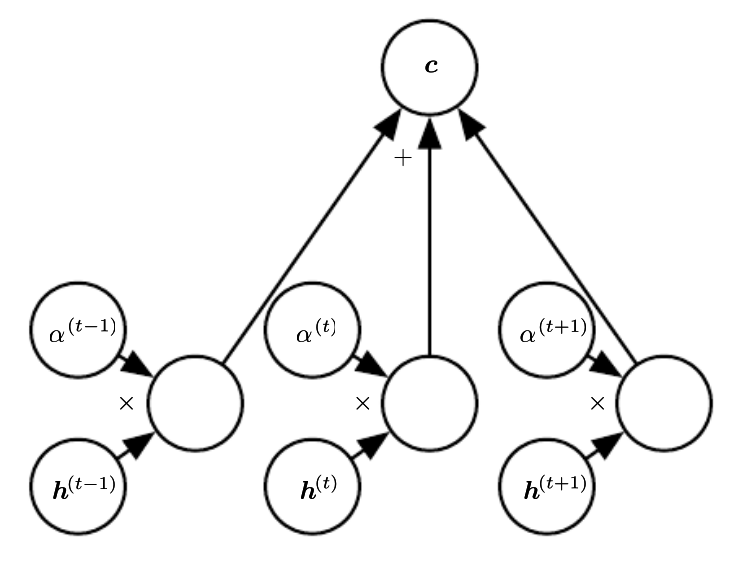
- Basically a weighted average of the encoder states, called the context
- Weights usually come from a softmax layer
- ❓ what does the use of softmax tell us about the weights?
Encoder-Decoder with Attention
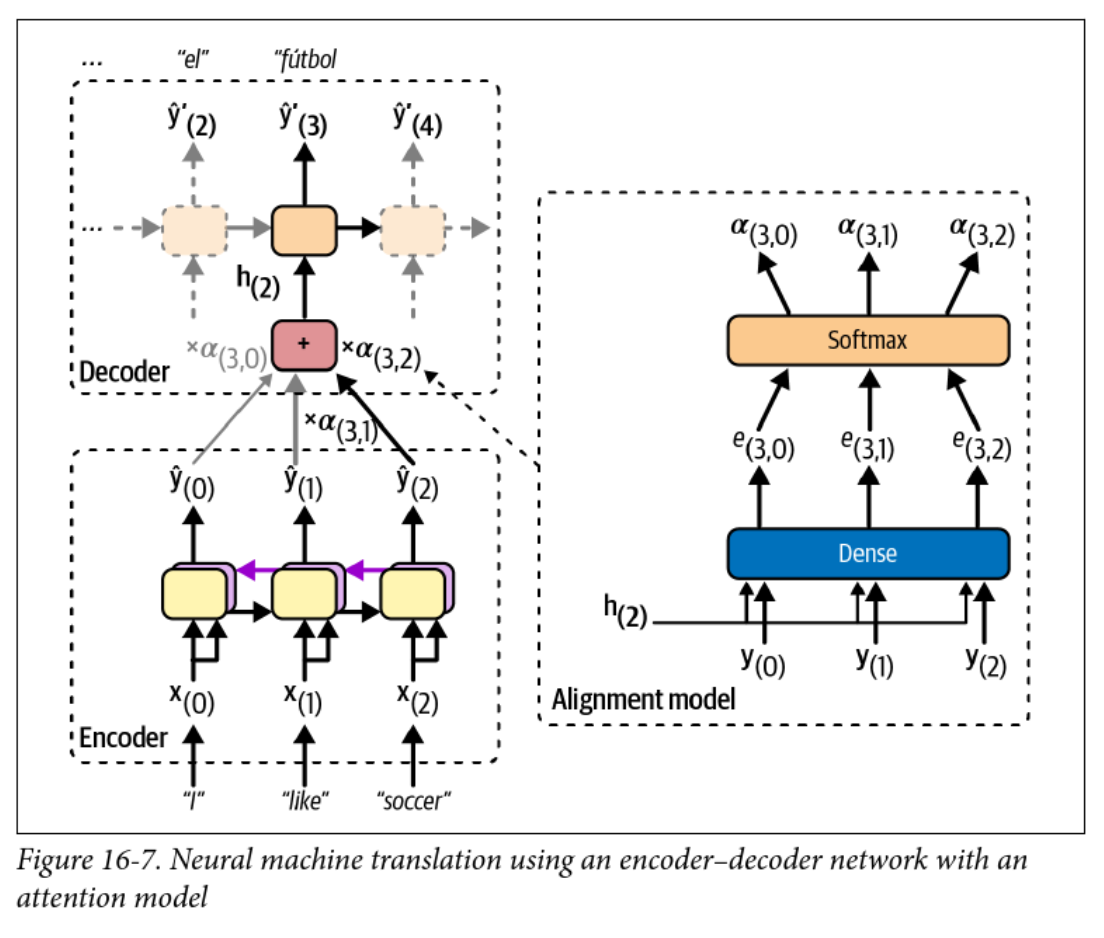
- The alignment model is used to calculate attention weights
- The context vector changes at each time step!
Attention Example

- Attention weights can be visualized as a heatmap
- ❓ What can you infer from this heatmap?
The math version
The context vector at each step is computed from the alignment weights as:
where is the encoder output at step and is computed as:
where is the alignment score or energy between the decoder hidden state at step and the encoder output at step .
Different kinds of attention
- The original Bahdanau attention (2014) model: where , , and are learned parameters
- Luong attention (2015), where the encoder outputs are multiplied by the decoder hidden state (dot product) at the current step
- ❓ What might be a benefit of dot-product attention?
Attention is all you need

- Some Googlers wanted to ditch RNNs
- If they can eliminate the sequential nature of the model, they can parallelize training on their massive GPU (TPU) clusters
- Problem: context matters!
- ❓ How can we preserve order, but also parallelize training?
Transformers
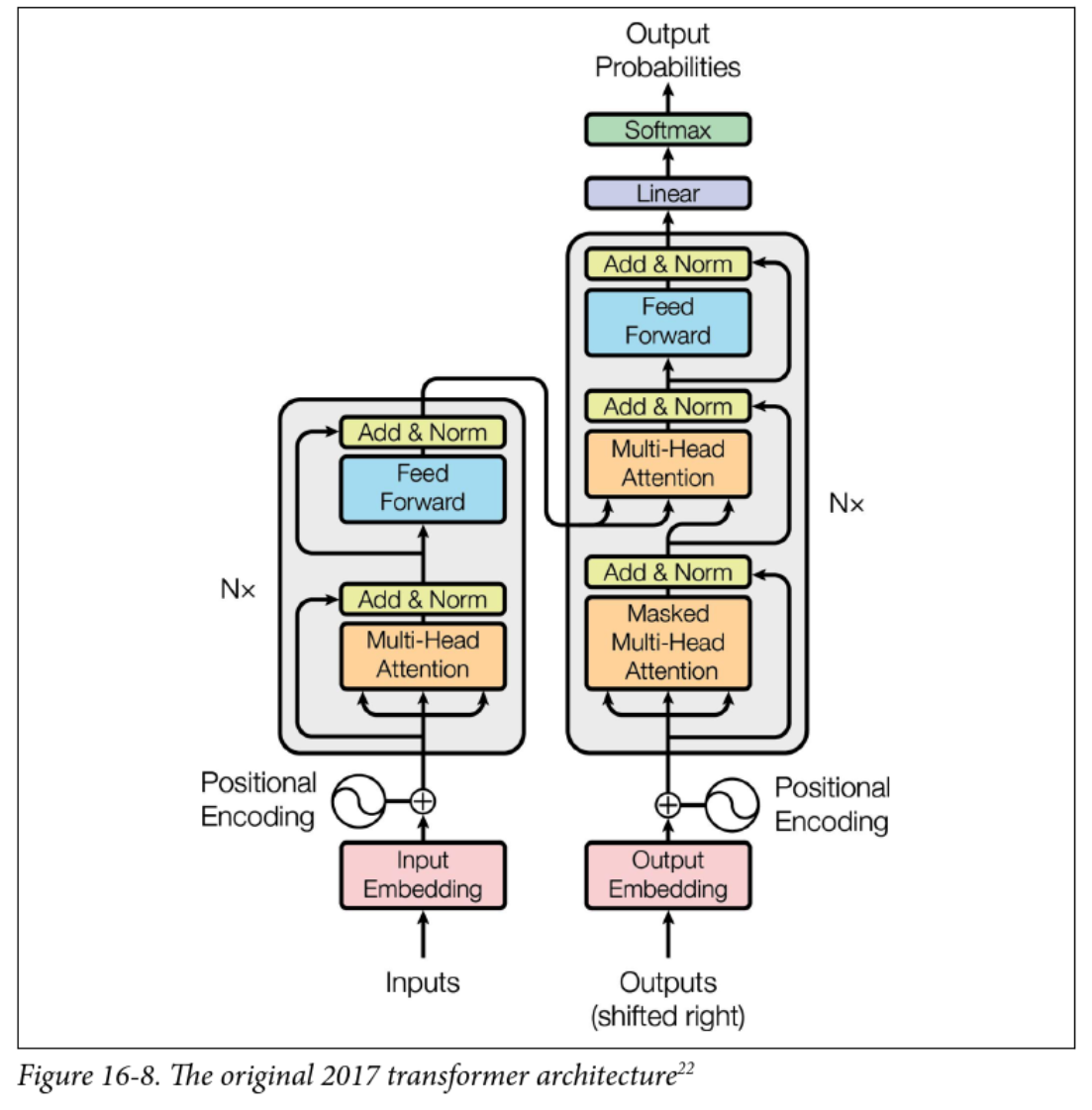
- Still encoder-decoder and sequence-to-sequence
- encoder/decoder layers
- New stuff:
- Multi-head attention
- Positional encoding
- Skip (residual) connections and layer normalization
Multi-head attention
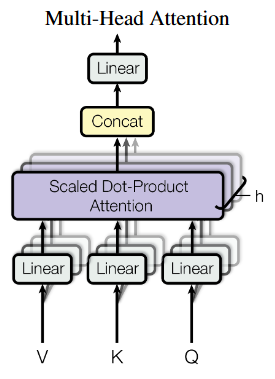
- Each input is linearly projected times with different learned projections
- The projections are aligned with independent attention mechanisms
- Outputs are concatenated and linearly projected back to the original dimension
- Concept: each layer can learn different relationships between tokens
What are V, K, and Q?
- Attention is described as querying a set of key-value pairs
- Kind of like a fuzzy dictionary lookup
- is an matrix, where is the dimension of the keys
- is an matrix
- is an matrix
- The product is , representing the alignment score between queries and keys (dot product attention)
The various (multi) attention heads
- Encoder self-attention (query, key, value are all from the same sequence)
- Learns relationships between input tokens (e.g. English words)
- Decoder masked self-attention:
- Like the encoder, but only looks at previously generated tokens
- Prevents the decoder from “cheating” by looking at future tokens
- Decoder cross-attention:
- Decodes the output sequence by “attending” to the input sequence
- Queries come from the previous decoder layer, keys and values come from the encoder (like prior work)
Positional encoding
- By getting rid of RNNs, we’re down to a bag of words
- Positional encoding re-introduces the concept of order
- Simple approach for word position and dimension :
- resulting vector is added to the input embeddings
- ❓ Why sinusoids? What other approaches might work?
Other positional encodings
- Appendix D of the new version of Hands-on Machine Learning goes into detail about positional encodings, particularly for very long sequences
- Sinusoidal encoding is no longer used in favour of relative approaches
- Introduces locality bias
- Removes early-token bias
- Example: learnable bias for position in , clamped to a max
- Only bias terms to learn, regardless of sequence length
Interpretability
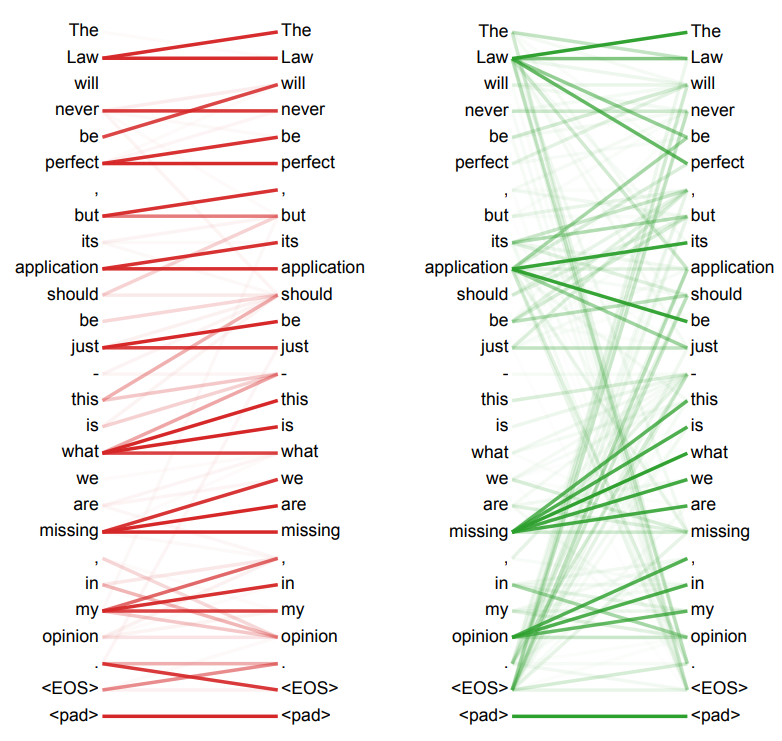
- The arXiv version of the paper has some fun visualizations
- This is Figure 5, showing learned attention from two different heads of the encoder self-attention layer
A smattering of Large language models
- GPT (2018): Train to predict the next word on a lot of text, then fine-tune
- Used only masked self-attention layers (the decoder part)
- BERT (2018): Bidirectional Encoder Representations from Transformers
- Train to predict missing words in a sentence, then fine-tune
- Used unmasked self-attention layers only (the encoder part)
- GPT-2 (2019): Bigger, better, and capable even without fine-tuning
- Llama (2023): Accessible and open source language model
- DeepSeek (2024): Significantly more efficient, but accused of being a distillation of OpenAI’s models
Hugging Face
-
Hugging Face provides a whole ecosystem for working with transformers
-
Easiest way is with the
pipelineinterface for inference:from transformers import pipeline nlp = pipeline("sentiment-analysis") # for example nlp("Cats are fickle creatures") -
Hugging Face models can also be fine-tuned on your own data