Lecture 8: Recurrent Neural Networks
 HTML Slides
HTML Slides PDF Slides
PDF SlidesRecurrent Neural Networks
COMP 4630 | Winter 2026 Charlotte Curtis
Overview
- Dealing with sequence data
- Feedforward vs recurrent networks
- References and suggested reading:
- Scikit-learn book: Chapter 15
- Deep Learning Book: Chapter 10
Sequence data
- So far we’ve been talking about images, tabular data, and other “static” data
- ❓ What are some examples of sequence data?
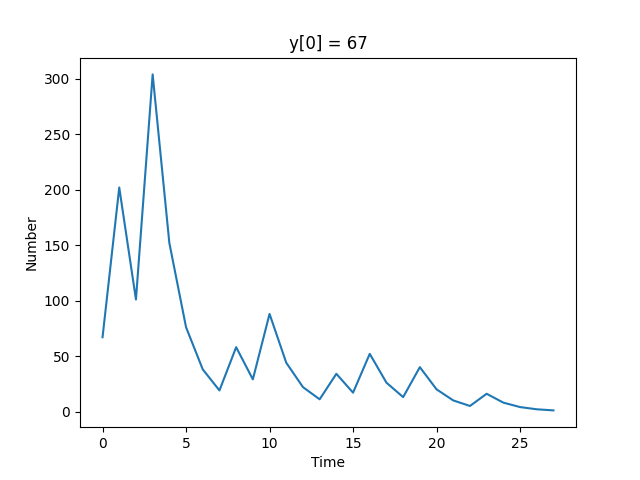
Non-RNN Approaches
As usual, you don’t always need a deep learning solution :hammer:
- ❓ What is an example of a “naive” approach?
- ❓ What are some limitations of naive approaches?
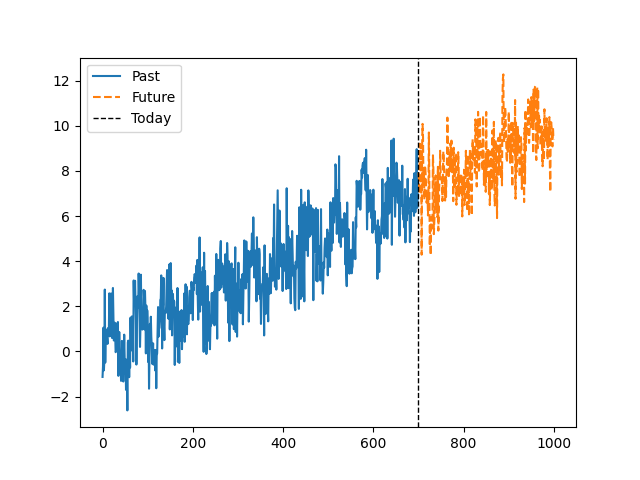
Autoregressive Moving Average
- Models to predict time series with a weighted average of past value where
- Key assumption: data is stationary (mean and variance don’t change)
- ARIMA adds on “integration” or “differencing” to account for trends
ARIMA
- Autoregressive parameter : How many steps back to average?
- Moving average parameter : How many previous errors to average?
- Integrative parameter : How many “differencing” rounds to perform before applying ARMA?
can be thought of as approximating the order polynomial
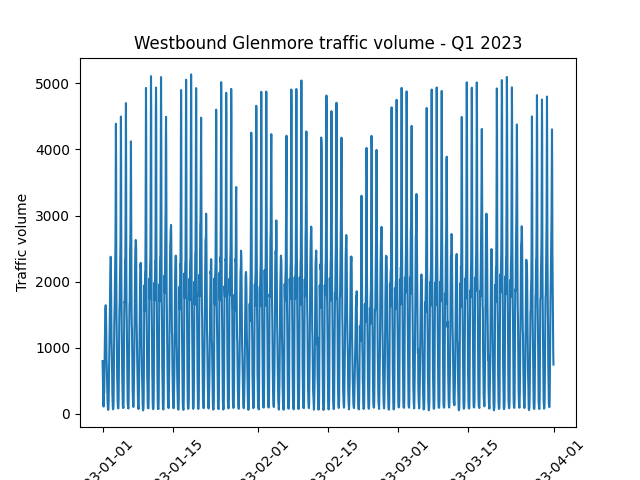
Trends, Seasonality, and Assumptions
- ❓ Are there any obvious trends in the data?
- ❓ What about non-obvious trends?
- ❓ How might this dataset be treated differently from the previous one?
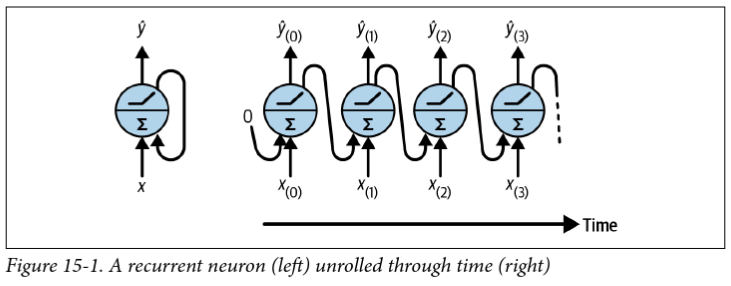
Feedforward vs recurrent networks
- Feedforward: data flows in one direction (then backpropagated)
- Recurrent: data can flow in loops
Recurrent layers
- The simplest recurrent layer has a single feedback connection where is the activation function and and are weight matrices
- “Backpropagation through time” (BPTT) is exactly the same as regular backpropagation through the unrolled network
- ❓ What kind of issues might arise during training?
- ❓ What are some limitations of this approach?
- ❓ How can we deal with for ?
Preparing data for RNNs
- The data format depends on the task, e.g. do you want to predict:
- The next value in a sequence (e.g. predictive text)
- The next values in a sequence (e.g. stock prices)
- The next sequence in a set of sequences (e.g. language translation)
- Let’s start with predicting the next value in a sequence

Activation Functions for RNNs
- The default activation function in tensorflow/PyTorch is
tanh - ❓ What is different about RNNs that might influence the choice of activation function?
- ❓ How might we normalize sequence data?
Beyond the “next value”
- Option 1: Use the single-prediction RNN repeatedly
- Option 2: Train the RNN to predict multiple values at once
- Easy change model-wise, but data preparation is trickier
ninputs,noutputs
- Option 3: Use a “sequence to sequence” model
- Even trickier data preparation, but
ninputs are predicted at each time step instead of just at the end
- Even trickier data preparation, but
Seq2seq input/target examples
| Input | Target | |
|---|---|---|
| 1 | [0, 1, 2] | [1, 2, 3] |
| 2 | [0, 1, 2] | [[1, 2], [2, 3], [3, 4]] |
| 3 | [0, 1, 2] | [[1, 2, 3], [2, 3, 4], [3, 4, 5]] |
Problems with long sequences
- Gradient vanishing/exploding
- Choose activation functions and initialization carefully
- Consider “Layer normalization” (across features)
- “Forgetting” early data
- Skip connections through time
- “Leaky” RNNs
- Long short-term memory (LSTM)
- Computational efficiency and memory constraints
- Gated recurrent units (GRUs)
Skip connections and leaky RNNs
- Simple way of preserving earlier data:
- Vanilla RNN: depends on only
- Skip connection: depends on , , , etc.
- Leaky RNN has a smooth “self-connection” to dampen the exponential:
- Not common approaches anymore, as LSTM, GRU, and especially attention mechanisms are more popular
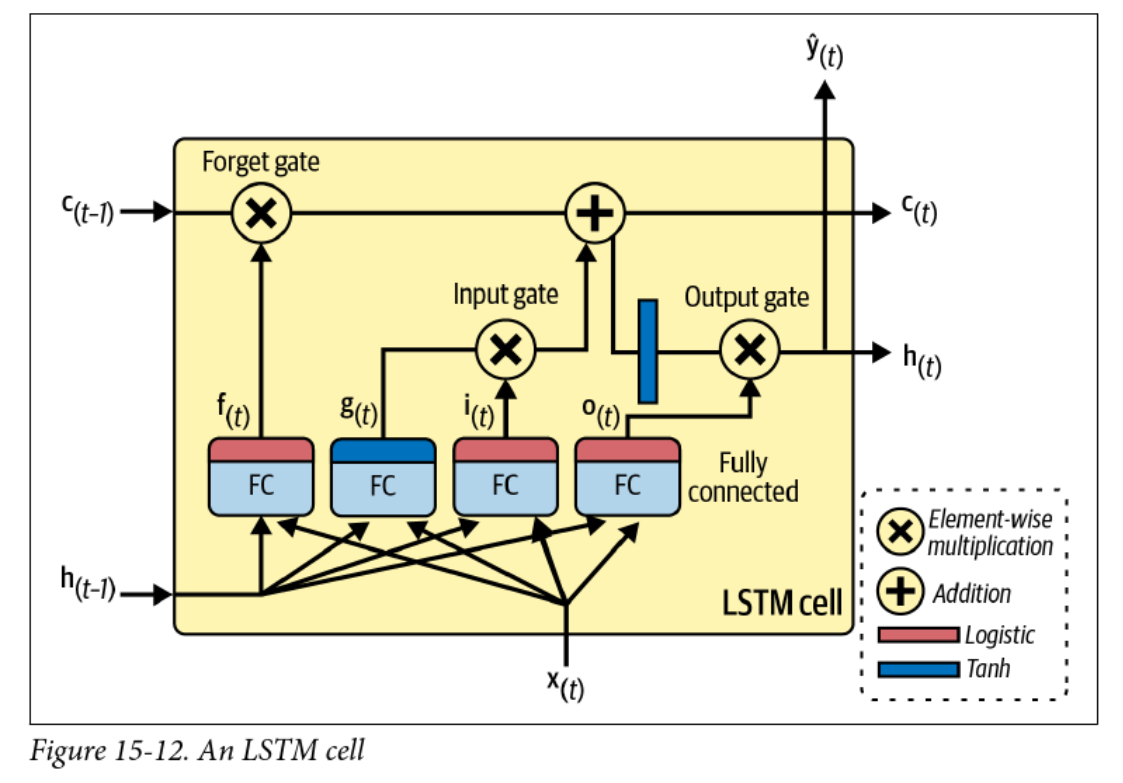
Long Short-Term Memory (LSTM)
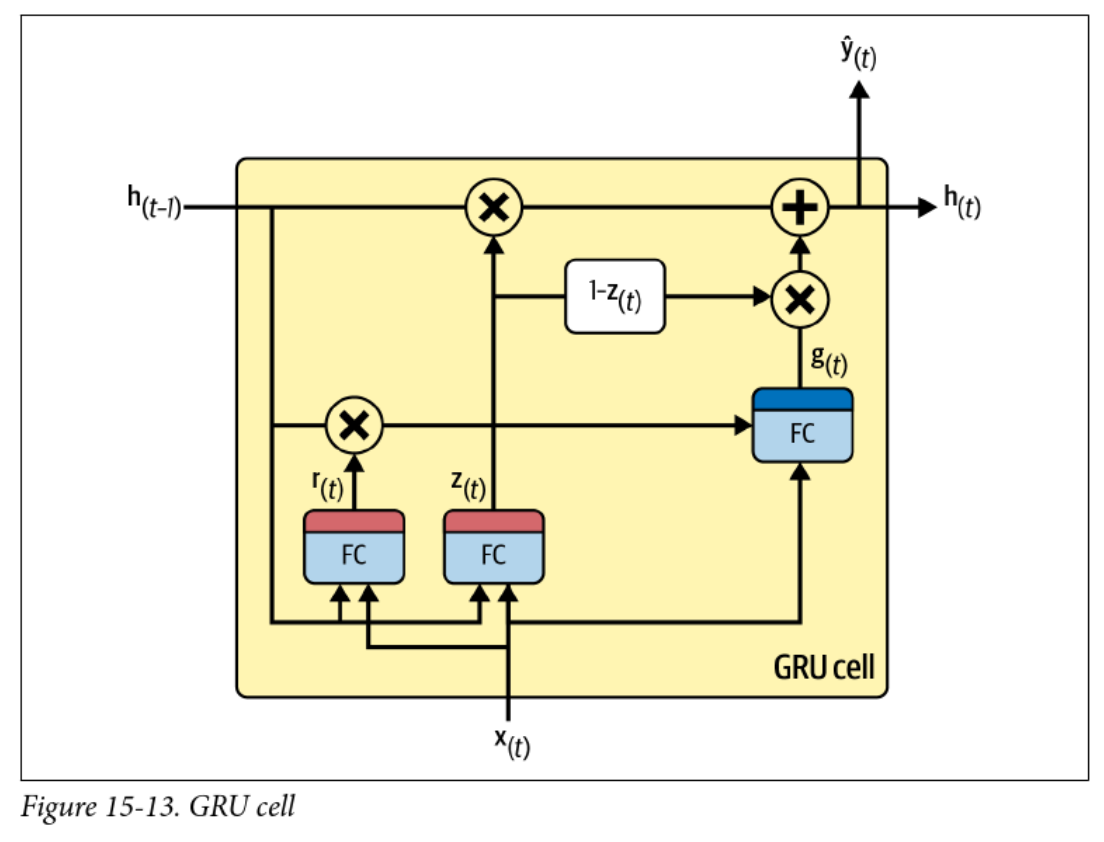
Gated Recurrent Units (GRUs)
Next up: Natural Language Processing
Preview: Natural Language Processing
- Natural Language Processing (NLP) is a field of study that focuses on the interaction between computers and human language.
- RNNs are widely used in NLP tasks such as language modeling, machine translation, sentiment analysis, and text generation.
- Language modeling involves predicting the next word in a sequence of words, which can be done using RNNs.
- Machine translation uses RNNs to translate text from one language to another.
- Sentiment analysis aims to determine the sentiment or emotion expressed in a piece of text, and RNNs can be used for this task.
- Text generation involves generating new text based on a given input, and RNNs are commonly used for this purpose.
Preview: Natural Language Processing
- What is Natural Language Processing (NLP)?
- Common NLP tasks:
- Language modeling
- Machine translation
- Sentiment analysis
- Text generation
- How RNNs are applied in NLP
Preview: Natural Language Processing
- NLP in 2026 is dominated by large language models (LLMs) like GPT-4o, Claude, and Gemini
- Transformer-based architectures have largely replaced RNNs for most NLP tasks
- Key capabilities of modern NLP systems:
- Multi-modal understanding (text, images, audio, video)
- Long-context reasoning (millions of tokens)
- Agentic behaviour: tool use, planning, and self-correction
- ❓ If transformers have replaced RNNs, why are we still studying them?