Lecture 2: Math Review
 HTML Slides
HTML Slides PDF Slides
PDF SlidesMath review
COMP 4630 | Winter 2026 Charlotte Curtis
Math review
- MATH 1203: Linear algebra
- MATH 1200: Differential calculus
- MATH 2234: Statistics
Further reading:
- Linear algebra: notebook, deep learning book
- Calculus: notebook
Linear algebra
Vectors are multidimensional quantities (unlike scalars):
A common vector space is , or the 2D Euclidean plane. Example:
Vector operations
- Addition:
- Scalar multiplication:
- Dot product: (yields a scalar)
- Can be thought of as the projection of one vector onto another, or how much two vectors are aligned in the same direction
Vector norms
- The norm of a vector is a measure of its length
- Most common is the Euclidean norm (or norm):
- You might also see the norm, particularly as a regularization term:
Useful vectors
- Unit vector: A vector with a norm of 1, e.g. ,
- Normalized vector: A vector divided by its norm, e.g.
- Dot product can also be written as
Yes, a normalized vector is also a unit vector, main difference is in context and notation
Matrices
A matrix is a 2D array of numbers:
Notation: Element is in row , column , also written as .
Rows then columns! matrix has rows and columns
Matrix operations
- Addition: element-wise if dimensions match.
- Scalar multiplication: just like vectors
- Matrix multiplication: where the elements of are:
- Multiply and sum rows of with columns of
- Usually,
Matrix multiplication examples
Matrix times a matrix:
Matrix times a vector:
Where we left off on January 14
Matrix transpose
-
Transpose: swaps rows and columns
-
Inverse: just as , , where is the identity matrix
Not every matrix is invertible!
Calculus: Notation
The derivative of a function is represented as:
The second derivative is denoted:
and so on.
Differentiability
For a function to be differentiable at a point , it must be:
- Defined at
- Continuous at
- Smooth at
- Non-vertical at
Select rules of differentiation
| Function | Lagrange | Leibniz | |
|---|---|---|---|
| Constant | |||
| Power | with | ||
| Sum | |||
| Exponential | |||
| Chain Rule |
Chain rule example
-
Find for
-
Now, let, , where . What is ?
Partial derivatives
For a scalar valued function , there are two partial derivatives:
These are computed by holding the “other” variable(s) constant. For example, if , then:
A brief introduction to vector calculus
Putting together partial derivatives with vectors and matrices we get:
Scalar-valued :
Vector-valued :
Most of the time we’ll just be working with the gradient
Statistics: Notation
- A random variable is a variable that can take on random variables according to some probability distribution
- may take on discrete (e.g. dice rolls) or continuous (e.g. age) values
- or for the random variable and or for a specific value
- for a a discrete distribution and for continuous
- and
Some textbooks/papers/websites use different notation!
Discrete random variables
- A discrete probability mass function describes the probability of taking on a specific value
- Example: for a balanced 6-sided die,
- You can add together probabilities, e.g.
- and for any valid distribution
Continuous random variables
- A continuous probability density function gives the probability of being in some tiny interval given by
- Example: the uniform distribution, for
- for any specific value
- Need to integrate to get a concrete value, e.g.
- and for any valid distribution
Expectation and variance
- The expectation or expected value is its average value
- and
- More generally, for any function :
- The variance describes how much the values vary from their mean:
Multiple random variables
- Joint probability is the probability of and occurring together
- Conditional probability is the probability that takes on value given that has already happened
- In general,
- For independent variables,
Covariance
- The covariance between and gives a sense of how linearly related they are and how much they vary together:
- Related to correlation as
- The covariance matrix of a random vector is a square matrix where the element is the covariance between and
- The diagonal of the covariance matrix gives
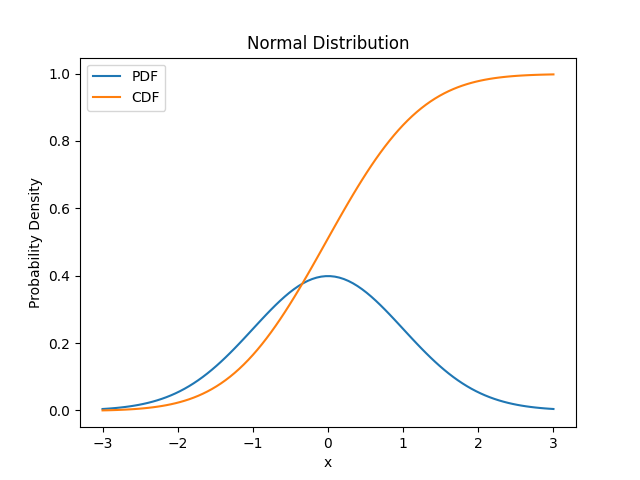
The Normal distribution
Good “default choice” for two reasons:
- The central limit theorem shows that the sum of many ( ish) independent random variables is normally distributed
- Has the most uncertainty of any distribution with the same variance
We can’t easily integrate , so numerical approximations are used
Coming up next
- Training (regression) models
- Linear regression
- Gradient descent
- References and suggested reading:
- Scikit-learn book:
- Chapter 4: Training Models
- Deep Learning Book
- Section 5.1.4: Linear Regression
- Scikit-learn book: